数据库
mysql
MySQL逻辑架构
mysql索引
mysql性能分析(explain)
mysql事务
MVCC
SQL JOINS
本文档使用 MrDoc 发布
-
+
首页
mysql索引
## 简介 影响性能、SQL慢体现在:执行时间长或者等待时间长 影响sql性能的常见情况: - 数据过多:分库分表 - 关联了太多的表,太多join:SQL优化 - 没有充分利用到索引:索引建立 - 服务器调优及各个参数设置:调整my.cnf MySQL官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构。 可以得到索引的本质:<font color='red'>索引是数据结构。</font> 索引的目的在于<font color='red'>提高查询效率</font>,可以类比字典。 **结论**: **数据本身之外,数据库还维护着一个满足特定查找算法的数据结构,这些数据结构以某种方式指向数据,这样就可以在这些数据结构的基础上实现高级查找算法,这种数据结构就是索引。** ## 索引的优劣势 **优势**: 1. 类似大学图书馆建书目索引,<font color='red'>提高数据检索的效率</font>,降低数据库的IO成本。 2. 通过索引列对数据进行排序,<font color='red'>降低数据排序和分组的成本</font>,降低了CPU的消耗。 3. 加速表和表之间的连接,对于有依赖关系的子表和父表联合查询时,可以提高查询速度。 **劣势**: 1. 虽然索引大大提高了查询速度,同时却会<font color='red'>降低更新表的速度</font>,如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件。每次更新添加了索引列的字段,都会调整因为更新所带来的键值变化后的索引信息 2. 实际上索引也是一张表,该表保存了主键与索引字段,并指向实体表的记录,所以<font color='red'>索引列也是要占用空间的</font> ## MySQL的索引结构 ### BTree索引 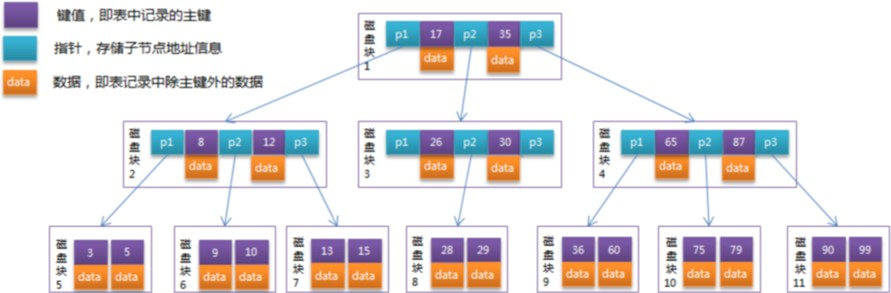 **初始化介绍** 一颗b树,包含多个磁盘块,可以看到每个磁盘块包含几个键值(表中记录的主键)、数据(表中除主键外的数据)和指针(指向下一个磁盘块的指针)如磁盘块1包含键值17和35,包含指针P1、P2、P3,P1表示小于17的磁盘块,P2表示在17和35之间的磁盘块,P3表示大于35的磁盘块。真实的数据存在于叶子节点即3、5、9、10、13、15、28、29、36、60、75、79、90、99。非叶子节点不存储真实的数据,只存储指引搜索方向的键值信息,如17、35并不真实存在于数据表中。 **查找过程** 如果要查找数据项29,那么首先会把磁盘块1由磁盘加载到内存,此时发生一次IO,在内存中用二分查找确定29在17和35之间,锁定磁盘块1的P2指针,内存时间因为非常短(相比磁盘的IO)可以忽略不计,通过磁盘块1的P2指针的磁盘地址把磁盘块3由磁盘加载到内存,发生第二次IO,29在26和30之间,锁定磁盘块3的P2指针,通过指针加载磁盘块8到内存,发生第三次IO,同时内存中做二分查找找到29,结束查询,总计三次IO。 真实的情况是,3层的b+树可以表示上百万的数据,如果上百万的数据查找只需要三次IO,性能提高将是巨大的,如果没有索引,每个数据项都要发生一次IO,那么总共需要百万次的IO,显然成本非常非常高。 ### B+Tree索引 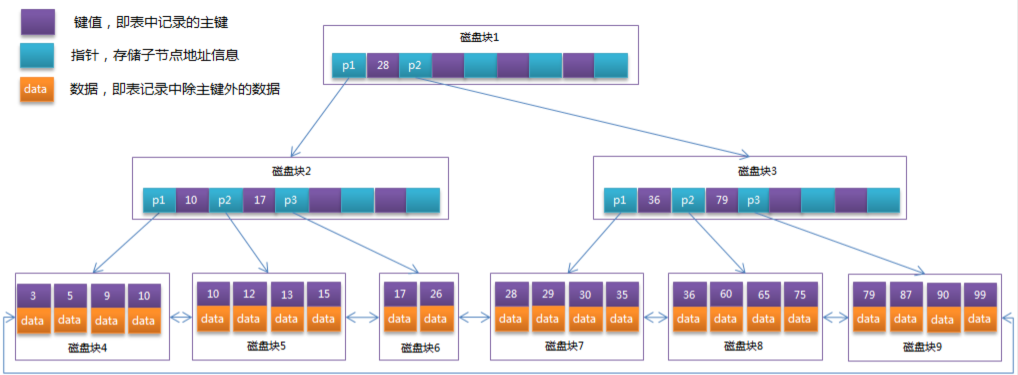 通常在B+Tree上有两个头指针,一个指向根节点,另一个指向关键字最小的叶子节点,而且所有叶子节点(即数据节点)之间是一种链式环结构。因此可以对B+Tree进行两种查找运算:一种是对于主键的范围查找和分页查找,另一种是从根节点开始,进行随机查找。通常在B+Tree上有两个头指针,一个指向根节点,另一个指向关键字最小的叶子节点,而且所有叶子节点(即数据节点)之间是一种链式环结构。因此可以对B+Tree进行两种查找运算:一种是对于主键的范围查找和分页查找,另一种是从根节点开始,进行随机查找。 ### B+Tree与B-Tree 的区别 1)B-树的关键字和记录是放在一起的,叶子节点可以看作外部节点,不包含任何信息;<font color='red'>B+树的非叶子节点中只有关键字和指向下一个节点的索引,记录只放在叶子节点中。</font> 2)在B-树中,越靠近根节点的记录查找时间越快,只要找到关键字即可确定记录的存在;而B+树中每个记录的查找时间基本是一样的,都需要从根节点走到叶子节点,而且在叶子节点中还要再比较关键字。从这个角度看B-树的性能好像要比B+树好,而在实际应用中却是B+树的性能要好些。因为B+树的非叶子节点不存放实际的数据,这样每个节点可容纳的元素个数比B-树多,树高比B-树小,这样带来的好处是减少磁盘访问次数。尽管B+树找到一个记录所需的比较次数要比B-树多,但是一次磁盘访问的时间相当于成百上千次内存比较的时间,因此实际中B+树的性能可能还会好些,而且B+树的叶子节点使用指针连接在一起,方便顺序遍历(例如查看一个目录下的所有文件,一个表中的所有记录等),这也是很多数据库和文件系统使用B+树的缘故。 ### 为什么说B+树比B-树更适合实际应用中操作系统的文件索引和数据库索引? **B+树的磁盘读写代价更低** B+树每个盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了。 **B+树的查询效率更加稳定** 由于非叶子节点只包含键值和下一节点的指针,只有叶子节点才有具体数据项。所以任何关键字的查找必须走一条从根节点到叶子节点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。 ## 聚簇索引与非聚簇索引 **聚簇索引**:将数据存储与索引放到了一块,找到索引也就找到了数据 **非聚簇索引**:非聚集索引又叫辅助索引,叶子节点并不包含行记录数据,而是存储了聚集索引键。辅助索引访问数据总是需要二次查找(**回表**),每个表可以有多个辅助索引。 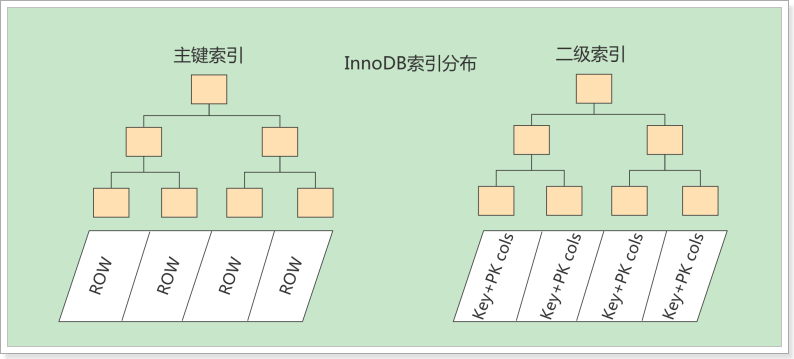 InnoDB使用的是聚簇索引,将**主键组织到一棵B+树**中,而**行数据就储存在叶子节点**上,若使用"where id = 14"这样的条件查找主键,则**按照B+树的检索算法即可查找到对应的叶节点,之后获得行数据**。 若**对Name列进行条件搜索,则需要两个步骤**:**第一步在辅助索引B+树中检索Name,到达其叶子节点获取对应的主键**。第二步**使用主键在主索引B+树种再执行一次B+树检索操作,最终到达叶子节点即可获取整行数据**。(**重点在于通过其他键需要建立辅助索引**) **聚簇索引的好处**: - 由于**行数据和叶子节点存储在一起,同一页中会有多条行数据,访问同一数据页不同行记录时,已经把页加载到了Buffer中,再次访问的时候,会在内存中完成访问**,不必访问磁盘。这样**主键和行数据是一起被载入内存的,找到叶子节点就可以立刻将行数据返回**了,**如果按照主键Id来组织数据,获得数据更快**。 - 聚簇索引适合用在排序的场合,非聚簇索引不适合 - 取出一定范围数据的时候,使用聚簇索引 **聚簇索引的限制**: - 对于mysql数据库目前只有innodb数据引擎支持聚簇索引,而Myisam并不支持聚簇索引。 - 由于数据物理存储排序方式只能有一种,所以每个Mysql的表只能有一个聚簇索引 - 一般情况下就是该表的主键。 - 如果没有定义主键,将会用第一个`UNIQUE`且`NOT NULL`的列来作为聚集索引。 - 如果表没有合适的`UNIQUE`索引,会内部根据行ID值生成一个隐藏的聚簇索引`GEN_CLUST_INDEX`。 - 为了充分利用聚簇索引的聚簇的特性,所以innodb表的主键列尽量选用有序非空的字段,而不建议用无序的id,比如uuid这种。 ## MySQL索引分类 1. 主键索引:设定为主键后数据库会自动建立索引,innodb为聚簇索引 2. 单值索引:即一个索引只包含单个列,一个表可以有多个单列索引 3. 唯一索引:索引列的值必须唯一,但允许有空值 4. 复合索引:即一个索引包含多个列 ## 索引的使用场景 哪些情况需要创建索引: - 主键自动建立唯一索引 - 频繁作为查询条件的字段应该创建索引 - 查询中与其它表关联的字段,外键关系建立索引 - 单键/组合索引的选择问题, 组合索引性价比更高 - 查询中排序的字段,排序字段若通过索引去访问将大大提高排序速度 - 查询中统计或者分组字段 哪些情况不要创建索引: - 表记录太少 - 经常增删改的表或者字段。 Why:提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件 - Where条件里用不到的字段不创建索引 - 过滤性不好的字段不适合建索引 ## 索引优化 ### 单表优化 #### 索引优化原则 1. 在索引列上有其他操作(**计算、函数、(自动or手动)类型转换**)导致索引失效 2. **like以通配符开头**('%abc...')导致索引失效 3. **不等于(!=或者<>)**导致索引失效 4. **is not null** 也无法使用索引,但是is null是可以使用索引的 5. **字符串不加单引号**导致索引失效 #### 组合索引原则 1. 全值匹配我最爱 2. 符合最左原则:不跳过索引中的列。 3. 如果where条件中是OR关系,加索引不起作用 4. 存储引擎不能使用索引中范围条件右边的列 #### 小结 一般性建议: 1. 对于单键索引,尽量选择针对当前query过滤性更好的索引 2. 在选择组合索引的时候,当前Query中过滤性最好的字段在索引字段顺序中,位置越靠前越好。 3. 在选择组合索引的时候,尽量选择可以能够包含当前query中的where字句中更多字段的索引 4. 在选择组合索引的时候,如果某个字段可能出现范围查询时,尽量把这个字段放在索引次序的最后面 5. 书写sql语句时,尽量避免造成索引失效的情况 ### 子查询优化 尽量不要使用not in 或者 not exists ### 排序及分组优化 排序时以下三种情况不走索引:使用Using filesort 1. 无过滤,不索引 2. 顺序错,不索引 3. 方向反,不索引 ### 覆盖索引 #### 什么是覆盖索引 **理解方式一:**索引是高效找到行的一个方法,但是一般数据库也能使用索引找到一个列的数据,因此它不必读取整个行。毕竟索引叶子节点存储了它们索引的数据;当能通过读取索引就可以得到想要的数据,那就不需要回表读取了。一个索引包含了满足查询结果的数据就叫做覆盖索引。 **理解方式二:**非聚簇复合索引的一种形式,它包括在查询里的SELECT、JOIN和WHERE子句用到的所有列(即建索引的字段正好是覆盖查询条件中所涉及的字段)。 简单说就是:select 到 from 之间查询的列 <= 使用的索引列 + 主键 **好处:** 1. 避免Innodb表进行索引的二次查询(回表) 2. 可以把随机IO变成顺序IO加快查询效率 **缺点**:索引字段的维护总是有代价的。因此,在建立冗余索引来支持覆盖索引时就需要权衡考虑了。
admin
2025年2月22日 23:11
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Rancher
Jenkins
ADMIN-UI
VBEN-ADMIN-UI
RUST-FS
MinIO
mindoc
Markdown文件
PDF文档(打印)
分享
链接
类型
密码
更新密码